AI System Design
AI system design patterns and architecture for production. Covers memory systems, caching, LLM evaluation, observability, scalability, and architectural decisions every AI engineer needs to know.
Eight Labs
AI Builder Education · TheAIHow · Updated April 2026
What is AI System Design?
AI system design is the discipline of architecting production-grade AI applications that are reliable, cost-efficient, observable, and maintainable at scale. It applies the principles of distributed systems engineering to AI-specific components: language models, embedding pipelines, vector stores, evaluation frameworks, and prompt management systems. Unlike traditional software, AI systems are inherently probabilistic — the same prompt can produce different outputs on different runs, model providers can silently change behavior with updates, and quality regressions are invisible without proper evaluation infrastructure. This non-determinism demands patterns that don't exist in conventional engineering: semantic caching (caching by meaning, not exact input), model routing (dynamically selecting between models by task complexity and cost), LLM-as-judge evaluation (using AI to assess AI output quality at scale), and prompt versioning (treating prompt changes as versioned, deployable code artifacts that require testing before shipping). These patterns are what separate an AI prototype that works once from a production system that works reliably at scale.
Model inference costs represent 60-80% of total AI infrastructure spend for most production applications (a16z, 2024). Teams that implement semantic caching and model routing consistently report 40-60% reductions in inference costs without quality degradation. According to a 2024 analysis by Andreessen Horowitz, AI operational costs are the primary barrier preventing enterprise AI prototypes from reaching production.
The unique challenges of AI system design include non-deterministic component behavior (LLMs), latency/cost tradeoffs in model selection, prompt engineering as infrastructure, evaluation pipelines to catch regressions, and observability tooling designed for AI (not just traditional APM). Every architectural decision has cost implications that compound at scale.
At The AI How, our AI system design content is inspired by the patterns used in production AI systems at leading companies. We cover memory architectures, caching strategies for LLM outputs, evaluation harnesses, cost optimization through model routing, and the infrastructure patterns that separate proof-of-concept demos from production systems.
Key Concepts for AI Builders
- Caching LLM outputs (semantic caching with vector similarity) can reduce inference costs by 40-60% for many use cases
- Model routing — using smaller, faster models for simple tasks and larger models for complex reasoning — is the single biggest cost lever
- Evaluation pipelines must be built from day one, not after you notice quality degradation
- Prompt management as code (versioned, tested, deployed) is required at production scale
- Observability for AI requires tracking LLM-specific metrics: latency to first token, total tokens, model used, prompt version, and output quality scores
Videos on AI System Design

Every AI Agent Failure Is a Context Failure. Here's the 5-Layer Fix.
7 min · May 13, 2026
Your AI Agent Will Be Hacked. Here's the Architecture That Stops It.
13 min · May 6, 2026
Claude Session Limits? Never Hit One Again
17 min · Apr 24, 2026
97% of AI Agents Fail in Production. Here's How to Build One That Doesn't
6 min · Apr 19, 2026
Build Your First AI Voice Agent (Full Architecture)
11 min · Apr 14, 2026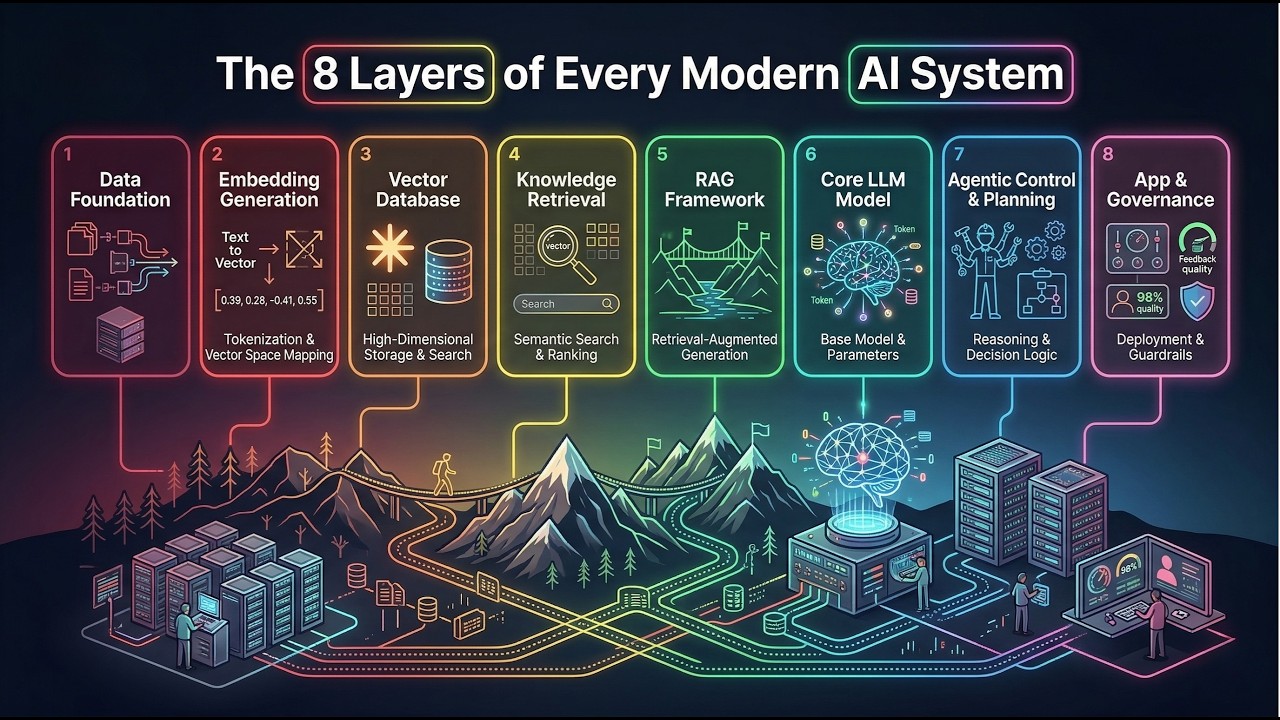
Why Most AI Engineers Build AI Wrong. The 8 Layer Reality
11 min · Apr 13, 2026
The 60% Problem Every Engineering Team Has
8 min · Apr 12, 2026
The AI Agent Platform War. Who ACTUALLY Wins?
7 min · Apr 11, 2026
The $0.08/hr AI Employee. Claude Managed Agents Pricing Breakdown
6 min · Apr 11, 2026Frequently Asked Questions
What is AI system design?
AI system design is the practice of architecting production AI applications. It covers decisions about model selection, data flow, memory systems, caching, evaluation pipelines, observability, and scalability. It bridges traditional software architecture with the unique properties of probabilistic AI components like LLMs.
How do I reduce LLM inference costs in production?
The highest-impact strategies: (1) model routing — use Haiku/GPT-4o-mini for simple tasks, save Sonnet/GPT-4 for complex reasoning, (2) semantic caching — cache LLM responses for similar queries, (3) prompt compression — reduce token count without losing context quality, (4) batching — group similar requests to take advantage of batch pricing.
How do I evaluate an LLM application in production?
Build an evaluation harness that tests your application on a golden dataset of representative inputs. Use LLM-as-judge (a separate LLM call to evaluate output quality) for semantic correctness. Track metrics over time: latency, token usage, output quality scores, and error rates. Tools like LangSmith, Helicone, and Braintrust make this significantly easier.
What is semantic caching and how does it work?
Semantic caching stores LLM responses and retrieves them when a similar (not identical) query is made. It works by embedding incoming queries and comparing them to cached query embeddings with a similarity threshold. When similarity is above the threshold (e.g., 0.95), return the cached response instead of calling the LLM. This can reduce costs by 40%+ for repetitive workloads.
More Topics for AI Builders
Built for AI Builders who ship.
New videos every week on AI System Design and the full AI builder stack. No fluff — only what you can apply in production immediately.
Subscribe on YouTube